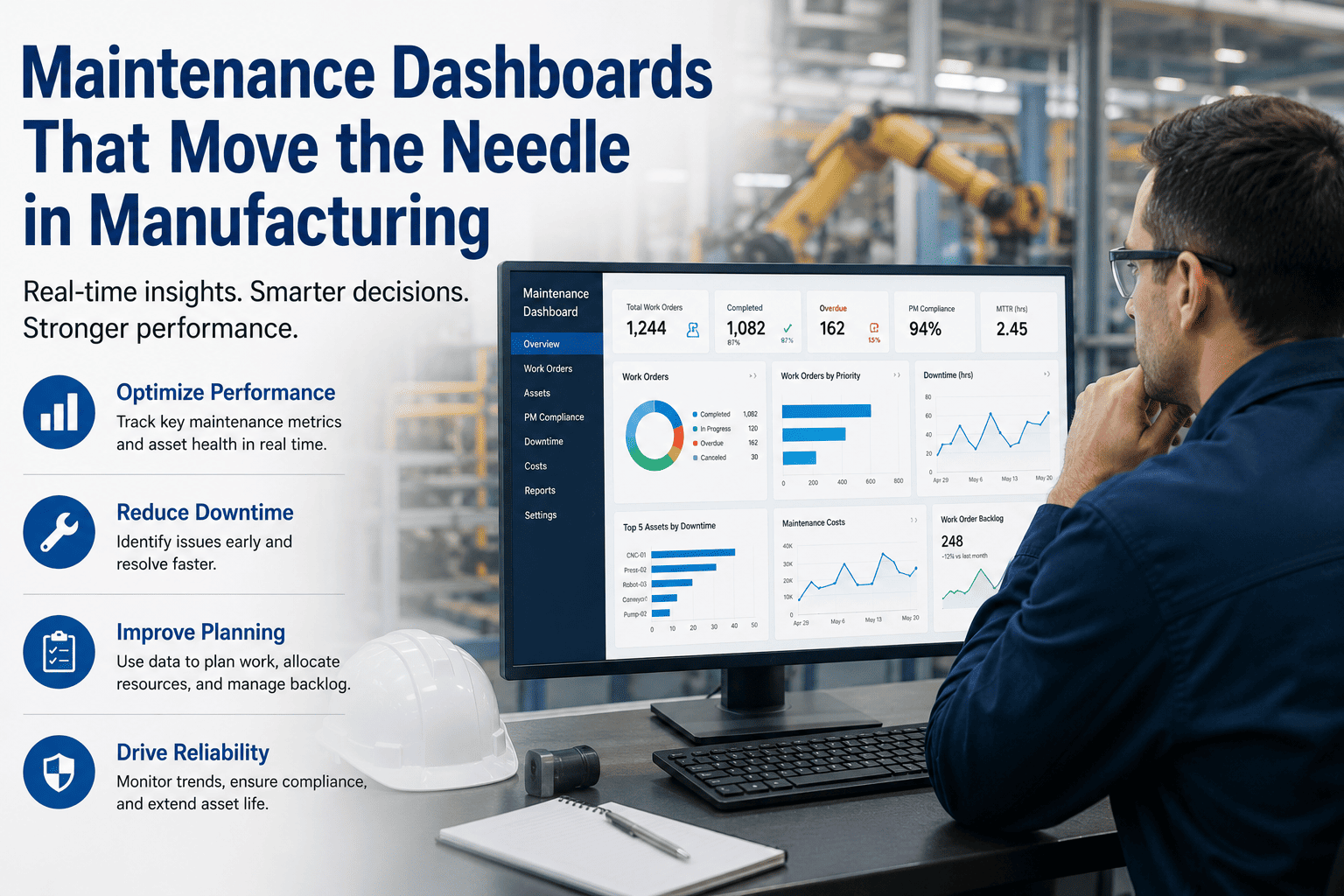
A pulp mill once ran a three-year study across more than 12,000 individual pieces of equipment. The finding: 87 items — less than 1% of the plant — caused 80% of all unscheduled downtime. Fixing those 87 cut unscheduled downtime by more than half within eighteen months. That is the Pareto principle doing exactly what it does best: showing reliability teams where four-fifths of the pain is actually coming from, instead of spreading effort evenly across a thousand things that barely matter. A CMMS like OxMaint builds this ranking automatically from your existing work order history.
Find Your Plant's Vital Few Automatically
Pareto-ranked downtime causes generated from your work order history — no manual spreadsheet sorting, no guessing which asset to fix first.
Why Reliability Teams Keep Spreading Effort Too Thin
The most common mistake in plant maintenance is treating every breakdown with equal urgency — a "peanut butter spread" of attention across every asset, every failure mode, every work order. The result is predictable: the trivial many get over-maintained, the vital few stay under-resourced, and the same handful of bad actors keep breaking month after month because nobody ever ring-fenced a project specifically for them.
Pareto analysis fixes this with a ranking exercise, not a judgment call. Sort downtime causes by total hours lost, find where the cumulative total crosses 80%, and everything to the left of that line is where the next reliability project belongs.
Worked Example: One Month of Downtime, Five Causes
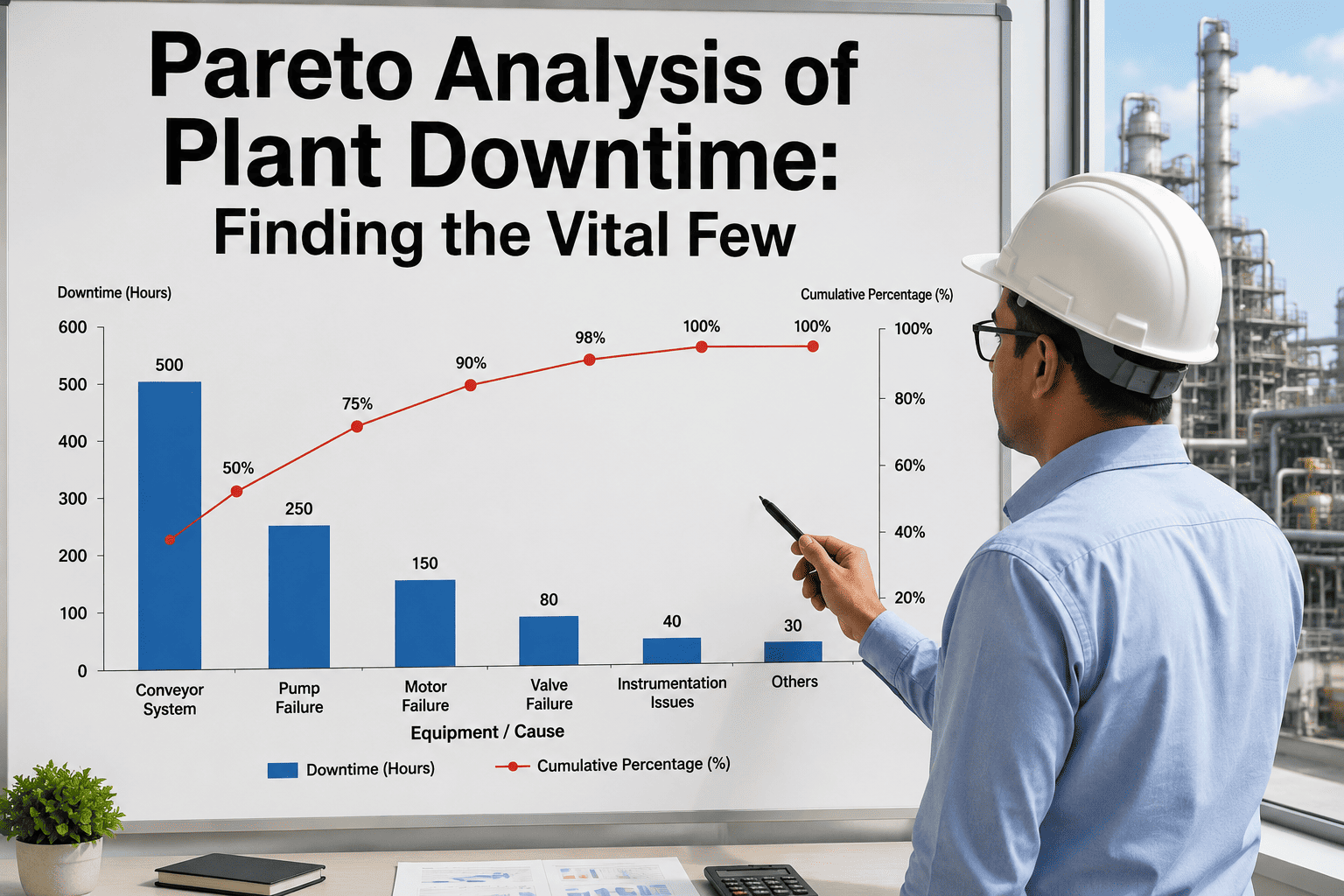
Take a packaging line that logged 142 hours of downtime last month across five recurring causes. Ranked by hours lost, the picture looks like this:
Seal failures, belt misalignment, and sensor faults — the first three bars — already account for 121 of the 142 hours, or 85% of total downtime. The cumulative line crosses 80% right at sensor fault. Jam clearance, changeover delay, and "other" together make up the remaining 15%, spread thin across causes that would each need a separate fix for a fraction of the benefit.
The Vital Few, Ranked
| Downtime Cause | Hours Lost | % of Total | Cumulative % |
|---|---|---|---|
| Seal Failure | 58h | 41% | 41% |
| Belt Misalignment | 39h | 27% | 68% |
| Sensor Fault | 24h | 17% | 85% |
| Jam Clearance | 12h | 8% | 93% |
| Changeover Delay | 6h | 4% | 97% |
| Other | 3h | 3% | 100% |
The action this points to is specific, not generic: a seal-integrity project on the asset behind the first bar, paired with a belt-alignment check, addresses 85% of this month's downtime with two focused interventions — not six scattered ones. Book a demo to see this ranking generated automatically from your own work order history instead of a manual spreadsheet sort.
Two Data Quality Checks Before You Trust the Ranking
Are Micro-Stops Captured?
PLC-only tracking that ignores stoppages under a few minutes can miss the majority of true downtime, skewing the ranking toward whatever happens to get logged.
Is the Failure Code Consistent?
"Sensor fault" logged three different ways across three shifts splits one real cause into three smaller bars, hiding it from the vital few entirely.
What the Vital Few Approach Actually Delivers
How OxMaint Builds the Pareto View For You
Automatic Downtime Capture
Every stoppage logged against a work order, including short stops easy to miss on a manual log or whiteboard.
Standardised Failure Codes
A consistent failure code list across shifts and sites, so the same root cause doesn't get split into several smaller, hidden ones.
Auto-Generated Pareto Ranking
Downtime causes ranked and charted automatically, with the 80% cutoff highlighted without anyone sorting a spreadsheet by hand.
Trend Tracking After Action
Re-run the ranking after a fix to confirm the vital few actually shrank, rather than assuming the project worked.
Stop Spreading Maintenance Effort Across the Trivial Many
Pareto-ranked downtime data generated automatically — so your next reliability project targets the cause actually costing you the most hours.
Frequently Asked Questions
Does the 80/20 split always hold exactly in maintenance data?
No. The ratio varies by plant and is often more extreme than 80/20 — one documented pulp mill study found less than 1% of assets responsible for 80% of unscheduled downtime. The principle is directional, not a precise law.
How do I build a Pareto chart from CMMS data?
Sort downtime causes by total hours lost in descending order, calculate each cause's percentage of the total, add a cumulative percentage column, and plot bars against the cumulative line. The cutoff sits where the line crosses 80%.
What's the most common mistake when running Pareto analysis on downtime?
Inconsistent failure coding. If the same root cause is logged under several different names across shifts, the true vital-few cause gets split into smaller entries and disappears from the top of the ranking.
Should Pareto analysis be run on hours lost or number of incidents?
Hours lost is usually more useful for prioritising reliability projects, since a cause with fewer but longer incidents can cost more total downtime than a cause with many short, low-impact stoppages.
How often should the Pareto ranking be re-run?
Monthly is typical for an active reliability programme. Re-running it after a fix is implemented also confirms whether the targeted cause actually dropped out of the vital few rather than just assuming the project worked.